

In the world of AI and machine learning, data is everything. However, raw data alone holds no real value until it is structured, labeled, and refined with pinpoint accuracy. Data annotation plays a critical role in training AI models, but here’s the catch: even the most advanced AI is only as good as the data it learns from. A single inconsistency or mislabeled data point can skew predictions, reduce model efficiency, and ultimately impact real-world applications.
This is where quality control in data annotation becomes indispensable. But what defines quality? And more importantly, how do we measure, monitor, and maintain it? Let’s break it down.
The Essence of Quality in Data Annotation
Quality in data annotation isn’t just about getting the labels right; it’s about precision, consistency, and reliability. Where a human annotator might interpret data with subtle variations, AI demands absolute uniformity. However, given the complexity of annotation tasks ranging from object detection in images to sentiment analysis in text, the room for error is vast.
The key is to implement rigorous quality control measures that can track errors, minimize inconsistencies, and refine the annotation process continuously.
Key Performance Indicators (KPIs) for Quality Control
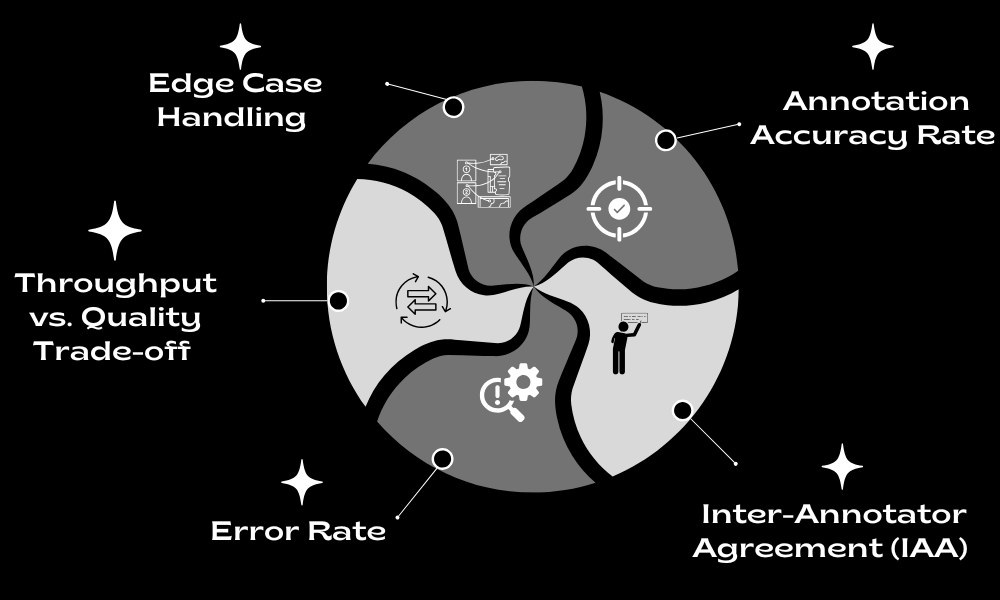
To ensure high-quality annotation, organizations must define measurable KPIs that evaluate the accuracy and efficiency of the labeling process. Some of the most critical KPIs include
- Annotation Accuracy Rate – Measures the percentage of correctly labeled data compared to a predefined ground truth. A high accuracy rate is non-negotiable, especially in sensitive AI applications such as medical imaging and autonomous driving.
- Inter-Annotator Agreement (IAA) – Evaluates the level of agreement between multiple annotators labeling the same dataset. A low IAA score indicates inconsistencies, whereas a high score ensures reliability.
- Error Rate – The percentage of incorrectly labeled data, which directly impacts model performance. This includes false positives, false negatives, and ambiguous annotations.
- Throughput vs. Quality Trade-off – While speed is essential, rushing through annotations often leads to errors. Measuring throughput while maintaining a minimum quality threshold helps balance efficiency with accuracy.
- Edge Case Handling – AI models often fail due to poorly annotated rare cases. Ensuring that edge cases are handled with extra scrutiny can significantly enhance model robustness.
Best Practices for Maintaining High-Quality Annotations
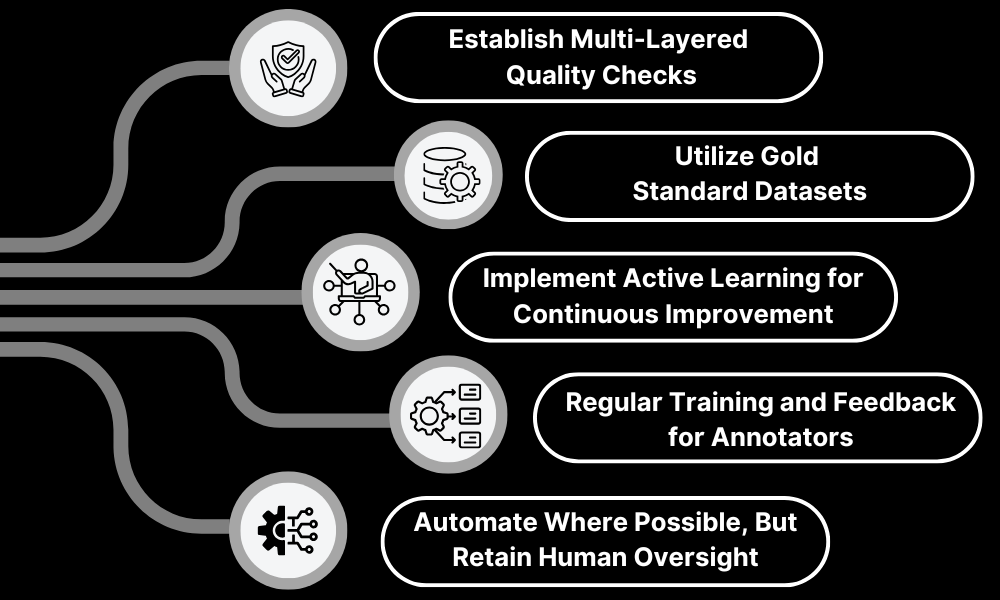
Establish Multi-Layered Quality Checks
Rather than relying on a single reviewer, high-quality annotation workflows incorporate multiple layers of validation. This includes peer reviews, automated quality checks, and subject-matter expert validation. While a basic annotation might pass an initial check, deeper scrutiny often reveals inconsistencies.
Utilize Gold Standard Datasets
Gold standard datasets serve as a benchmark for evaluating annotation accuracy. These are pre-labeled datasets validated by experts, providing a reference point against which annotations can be compared. However, creating such datasets requires meticulous effort and domain expertise.
Implement Active Learning for Continuous Improvement
Active learning techniques allow AI models to identify areas of uncertainty, prompting human annotators to focus on ambiguous cases. This iterative process helps refine datasets, making the annotation process smarter and more efficient over time.
Regular Training and Feedback for Annotators
Annotation is not a one-size-fits-all process. Different projects require different expertise, and even experienced annotators can make mistakes. Conducting ongoing training sessions, calibrating annotation guidelines, and providing constructive feedback ensures annotators stay aligned with project expectations.
Automate Where Possible, But Retain Human Oversight
Automation through AI-assisted annotation tools can speed up the process, but it is not foolproof. Whereas machines can process large volumes of data, humans excel at contextual understanding and subjective judgment. A hybrid approach leveraging automation while retaining human quality control strikes the perfect balance.
Final Thoughts: Quality Is Not an Option, It’s a Necessity
In data annotation, quality control is not a luxury, it’s a fundamental requirement. A single flaw in labeled data can cascade into model failures, leading to faulty AI decisions with real-world consequences. However, by defining clear KPIs, implementing best practices, and fostering a culture of precision, organizations can bridge the gap between raw data and AI excellence.
Ultimately, the goal is simple yet profound: ensuring that every data point contributes to building AI that is not just functional but exceptional.


ABOUT THE AUTHOR
Malvika
Malvika Agarwal is a dynamic marketing professional and content creator with a passion for crafting compelling brand stories. With a strong background in digital marketing, brand strategy, and creative content development, she excels at connecting brands with their audiences in meaningful ways. Malvika's expertise spans across various industries, where she has consistently driven growth and engagement through innovative marketing strategies. When she’s not creating impactful campaigns, Malvika enjoys sharing insights on marketing trends and exploring new creative outlets.


